c语言
lua
python爬虫兼职
自动生成
visual studio
机制与策略
RDF三元组
nginx
高光谱图像
技术群
macos
volatile
魔百盒固件
html静态页面
PC
IO流中的属性集
深度卷积神经网络
信号完整性仿真
图形化编程
申博
bs4
2024/4/19 22:50:33
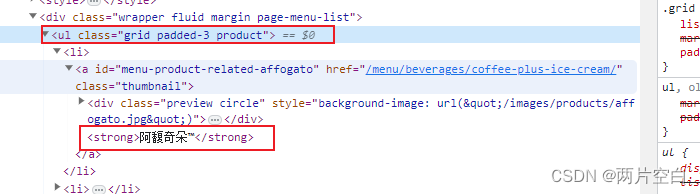
Scrapy与分布式开发(2.4):bs4+css基本指令和提取方法详解
bs4css基本指令和提取方法详解
CSS简介
CSS选择器是网页开发中不可或缺的工具,它们让我们能够精确地定位和选择HTML文档中的元素。在爬虫领域多用于从网页中提取和解析数据。本教程将结合网上教程,提供一份详细的CSS选择器使用指南,并深入探…
python——bs4解析网页数据
简介 bs4(Beautifulsoup)是html的解析器,主要的功能是解析和提取数据。 缺点是:效率不是很高。优点是:接口设计人性化,使用方便。
安装以及创建 1. 安装 pip install bs4 2. 导入 from bs4 import BeautifulSoup 3. 创建对象 服务…
3-爬虫-搜索文档树(find和find_all)、bs4其它用法、css选择器、selenium基本使用以及其他、selenium(无头浏览器、搜索标签)
1 搜索文档树 1.1 find和find_all 1.2 爬取美女图片 2 bs4其它用法 3 css选择器
4 selenium基本使用 4.1 模拟登录
5 selenium其它用法 5.1 无头浏览器 5.2 搜索标签
遍历文档树
-1 request 使用代理proxies {https: 192.168.1.12:8090,}-2 代理的使用-高匿 透明-免费---》…
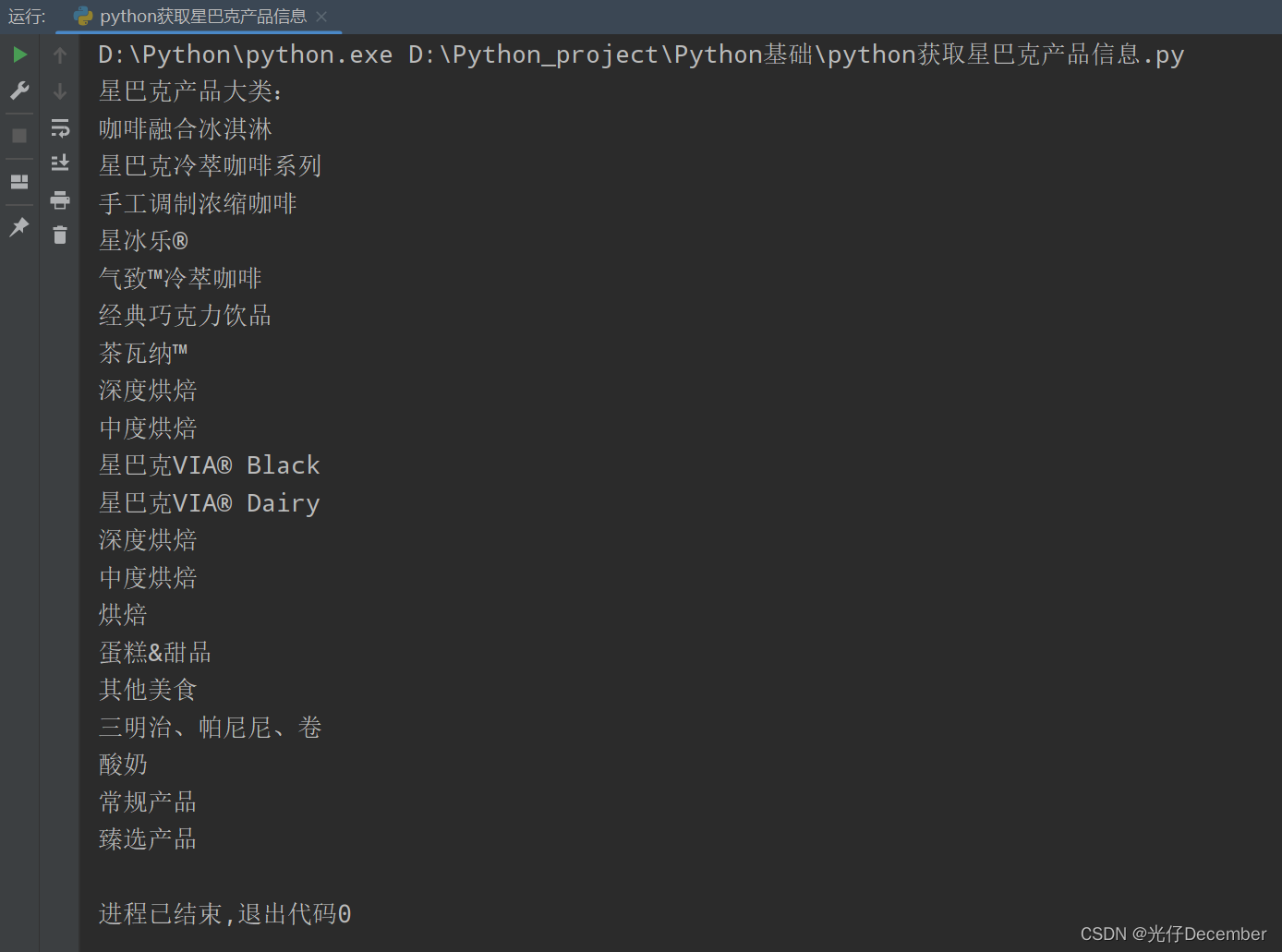
【Python从入门到进阶】33、使用bs4获取星巴克产品信息
接上篇《32、bs4的基本使用》 上一篇我们介绍了BeautifulSoup的基本概念,以及bs4的基本使用,本篇我们来使用bs4来解析星巴克网站,获取其产品信息。
一、星巴克网站介绍 星巴克官网是星巴克公司的官方网站,用于提供关于星巴克咖啡…
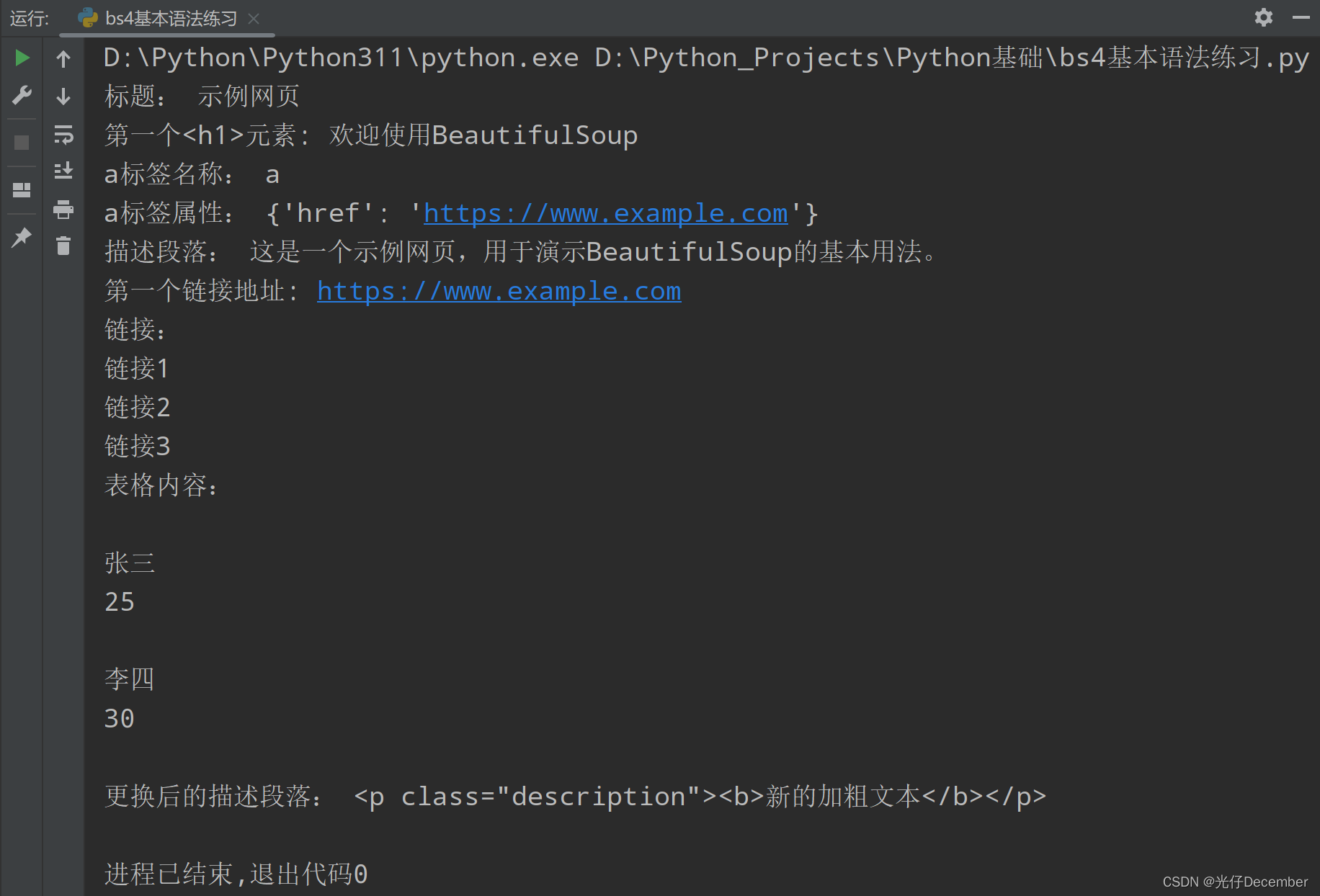
【Python从入门到进阶】32、bs4的基本使用
接上篇《31、使用JsonPath解析淘票票网站地区接口数据》 上一篇我们介绍了如何使用JSONPath来解析淘票票网站的地区接口数据,本篇我们来学习BeautifulSoup的基本概念,以及bs4的基本使用。
一、BeautifulSoup简介
1、bs4基本概念
BeautifulSoup是一个P…
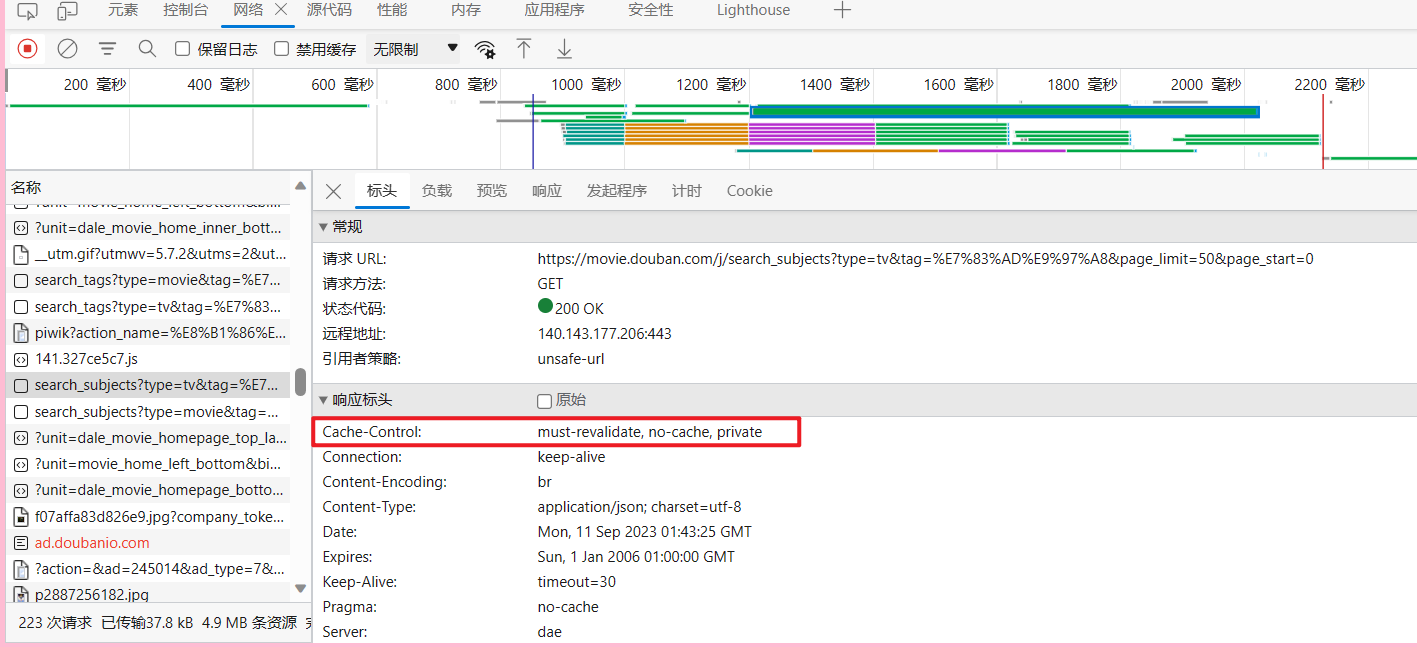
python系列:requests库+BS4库及综合实例
仅供学习、交流使用,不具有任何商业用途,如有问题请及时联系我们以作处理。 文章目录 前言requests安装使用第一种 requests.request("请求方式", ...)第二种 requests.请求方式(参数)URL中传递参数 paramsxx响应内容 r.text二进制响应内容 r.…

Python爬虫数据提取方式——使用bs4提取数据
爬虫网络请求方式:urllib(模块), requests(库), scrapy, pyspider(框架)爬虫数据提取方式:正则表达式, bs4, lxml, xpath, css测试HTML代码:首先导入
from bs4 import BeautifulSoup
序列化HTML代码
# 参数1:序列化的html源代码字…

大学生的小乐趣:python网页爬虫
网页Dev 网络爬虫主要看在网页的检查元素的这两个页面(Element、Network) Element :index页面的源代码(并且能进行快速的查找) Network:查找客户端和服务端之间的各种流
python Code
python里面含有多种框…
BeautifulSoup使用一两则(不定期补充)
Pycharm 5.0.3 IDE Pycharm BeautifulSoup 4.5.0
如何在Pycharm下安装BeautifulSoup请看 致力于打造最详细的Requests使用(不定期补充) 还有强烈推荐崔庆才–Python爬虫利器二之Beautiful Soup的用法不能更详细的用法介绍 都说BeautifulSoup是利器…